
Heads up! 🚧
In the meantime, feel free to check out my other projects or get in touch with me.
Thank you for your patience!
- Spencer
Open Karaoke Studio
Open Karaoke Studio is a modern, open-source web application that lets users generate instrumental karaoke tracks from their favorite songs using AI-powered vocal separation. Frustrated by the lack of available karaoke versions for many songs, I built this project to empower anyone to create their own karaoke tracks. The platform is designed for self-hosting, with a user-friendly React frontend and a Python/Flask backend leveraging Demucs for high-quality audio processing.

Project Goals
The main goal was to make AI-powered karaoke track generation accessible to everyone, especially for songs not available in traditional karaoke libraries. The project aims to provide a fast, modern, and self-hosted solution for karaoke enthusiasts, with a focus on usability, performance, and open-source collaboration.
My Role
- Sole Developer (Full-Stack)
Tech Choices
React 19 and TypeScript for a modern, type-safe frontend; Vite for fast builds; TanStack Query for data fetching; Zustand for state management; Tailwind CSS and Shadcn/UI for styling; Python 3.10+ and Flask for the backend API; Demucs and PyTorch for AI audio processing; Celery (planned) for async task handling; SQLAlchemy for database management; Socket.IO for real-time updates.
Key Features
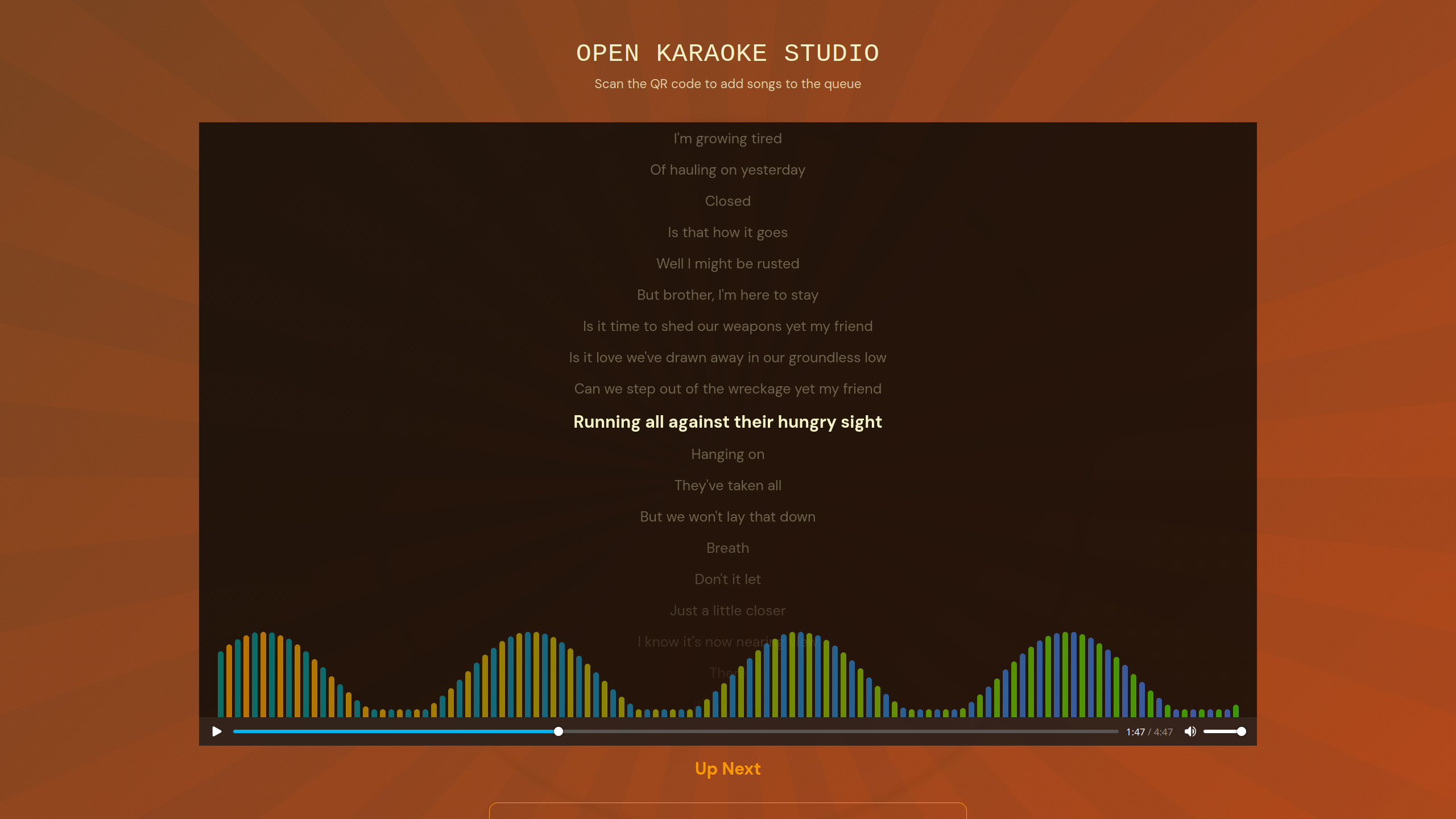
AI Vocal Separation
Generate karaoke tracks by separating vocals from music using Demucs.
Song Upload & Processing
Upload songs and process them asynchronously to create instrumentals.
Song Library
Manage and download your processed karaoke tracks in a user-friendly library.
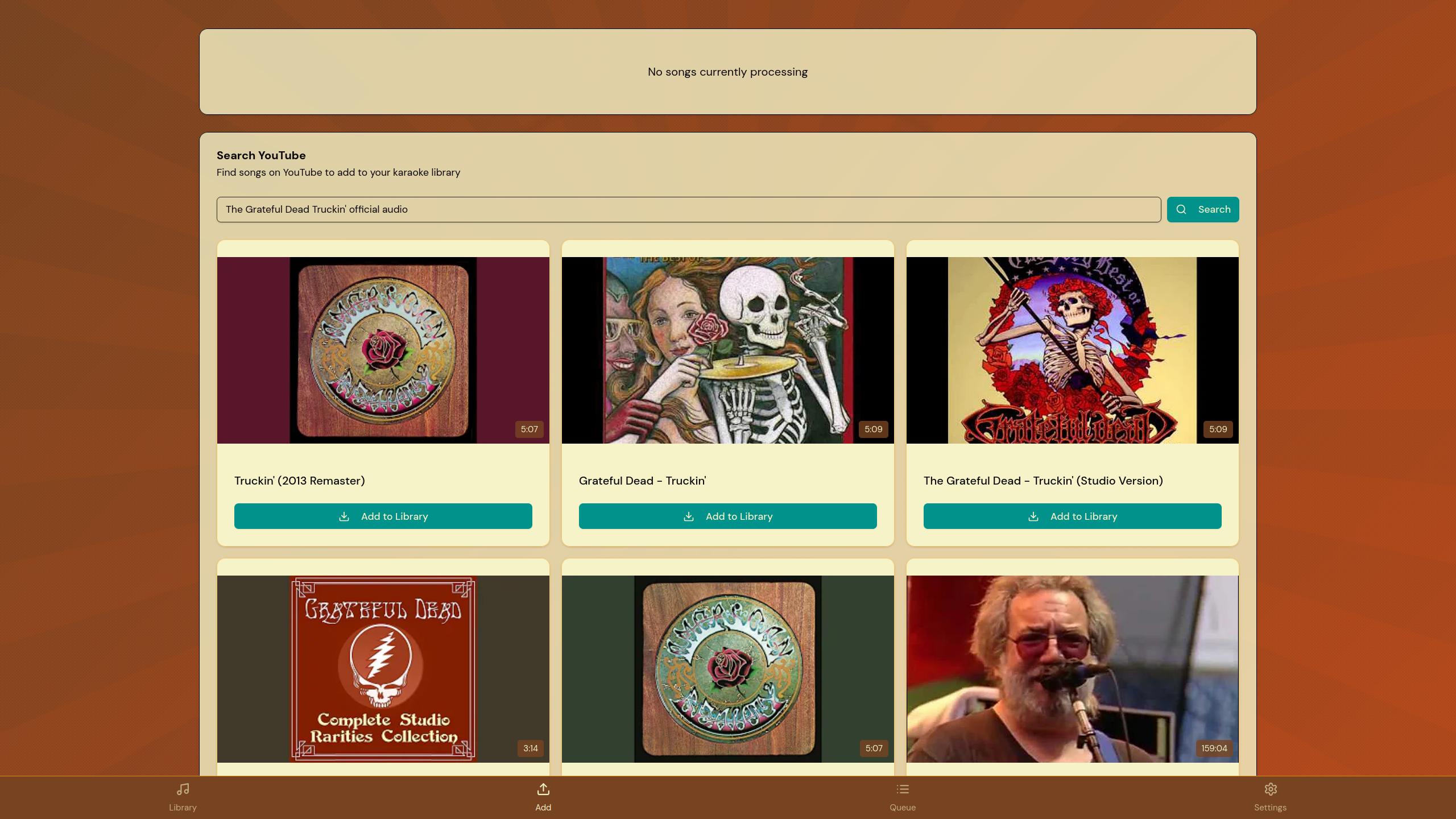
YouTube Song Search
Search for songs from YouTube and automatically generate karaoke tracks.
Modern Web Interface
Responsive, fast, and easy-to-use interface built with React, Tailwind, and Shadcn/UI.
Self-Hosting
Designed for easy self-hosting and personal use.
Challenges
Integrating AI audio separation (Demucs) into a web workflow
Managing asynchronous processing for long-running audio tasks
Building a seamless, modern user experience
Ensuring easy self-hosting and open-source contribution
Key Takeaways
This project deepened my experience with full-stack development, AI audio processing, and modern frontend tooling. I learned to integrate state-of-the-art machine learning models into a web workflow, manage asynchronous tasks, and design for both usability and maintainability. Open sourcing the project also gave me insight into documentation and community-driven development.